一、背景
YOLOv3出自论文《YOLOv3: An Incremental Improvement 》
论文地址:https://pjreddie.com/media/files/papers/YOLOv3.pdf
二、YOLOv3
话不多说,先上一张图作为本文的开胃菜吧(自认为这张图画的还是很清晰的,如果没什么基础的小伙伴,还是建议先看看YOLO基础)
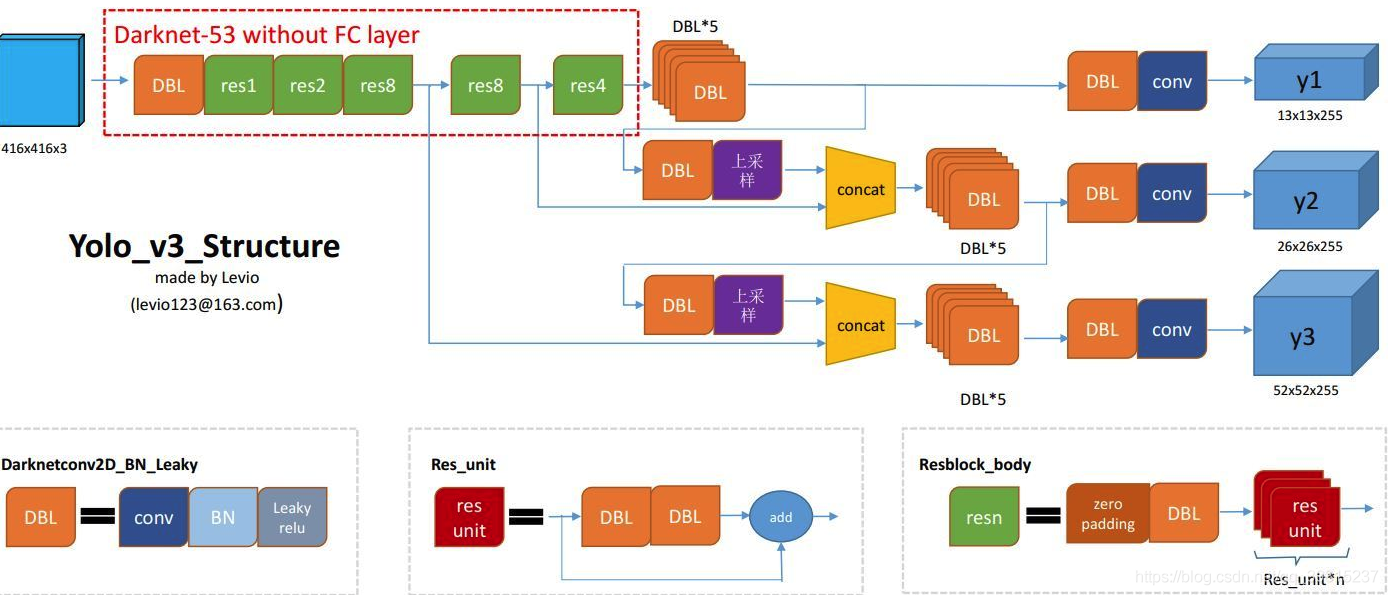
DBL: 如图左下角所示,也就是代码中的Darknetconv2d_BN_Leaky,是YOLOv3的基本组件。就是卷积+BN+Leaky relu。对于YOLOv3来说,BN和leaky relu已经是和卷积层不可分离的部分了(最后一层卷积除外),共同构成了最小组件。
res_n:n代表数字,有res1,res2, … ,res8等等,表示这个res_block里含有多少个res_unit。这是YOLOv3的大组件,YOLOv3开始借鉴了ResNet的残差结构,使用这种结构可以让网络结构更深(从YOLOv2的Darknet-19上升到YOLOv3的Darknet-53,前者没有残差结构)。对于res_block的解释,可以在图右下角直观看到,其基本组件也是DBL。
concat:张量拼接。将darknet中间层和后面的某一层的上采样进行拼接。拼接的操作和残差层add的操作是不一样的,拼接会扩充张量的维度,而add只是直接相加不会导致张量维度的改变。
整个YOLOv3_body包含252层,包括add层23层(主要用于res_block的构成,每个res_unit需要一个add层,一共有1+2+8+8+4=23层)。除此之外,BN层和LeakyReLU层数量完全一样(72层),在网络结构中的表现为:每一层BN后面都会接一层LeakyReLU。卷积层一共有75层,其中有72层后面都会接BN+LeakyReLU的组合构成基本组件DBL。看结构图,可以发现上采样和concat都有2次,和表格分析中对应上。每个res_block都会用上一个零填充,一共有5个res_block。
1.输入
YOLOv3延续了YOLOv2的输入部分,他的输入也是416×416的。
2.网络结构
backbone:Darknet-53
对比于YOLOv2使用的Darknet-19,YOLOv3使用了更为先进的Darknet-53。
整个YOLOv3结构里面,是没有池化层和全连接层的。前向传播过程中,张量的尺寸变换是通过改变卷积核的步长来实现的,比如stride=(2, 2),这就等于将图像边长缩小了一半(即面积缩小到原来的1/4)。在YOLOv2中,要经历5次缩小,会将特征图缩小到原输入尺寸的2的5次方分之一,即1/32.若输入为416×416,则输出为13×13(416/32=13)。
YOLOv3也和YOLOv2一样,backbone都会将输出特征图缩小到输入的1/32。所以,通常都要求输入图片是32的倍数。可以对比YOLOv2和YOLOv3的backbone看看:(DarkNet-19 与 DarkNet-53)
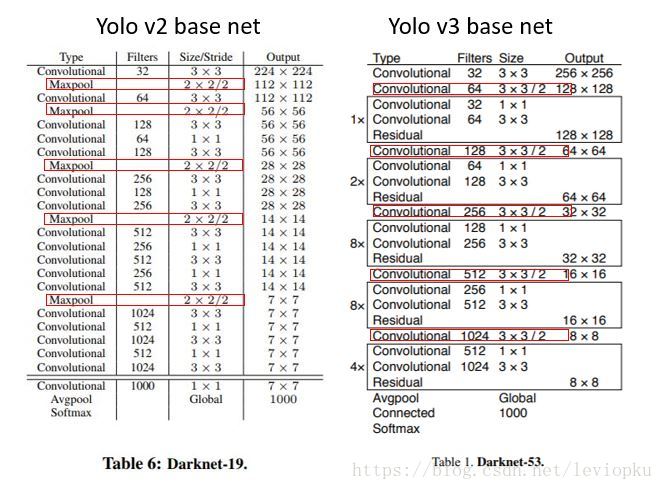
它借鉴了残差网络residual network的做法,在一些层之间设置了快捷链路(shortcut connections)。Darknet-53网络采用256×256×3作为输入,最左侧那一列的1、2、8等数字表示多少个重复的残差组件。每个残差组件有两个卷积层和一个快捷链路,示意图如下:
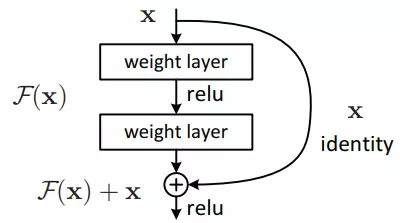
注释:为了解决Accuracy degradation problem(精度下降问题)和Gradient vanishing/exploding problem(梯度消失/爆炸问题)才使用了残差的概念。
3.利用多尺度特征进行对象检测
在YOLOv3更进一步采用了3个不同尺度的特征图来进行对象检测。
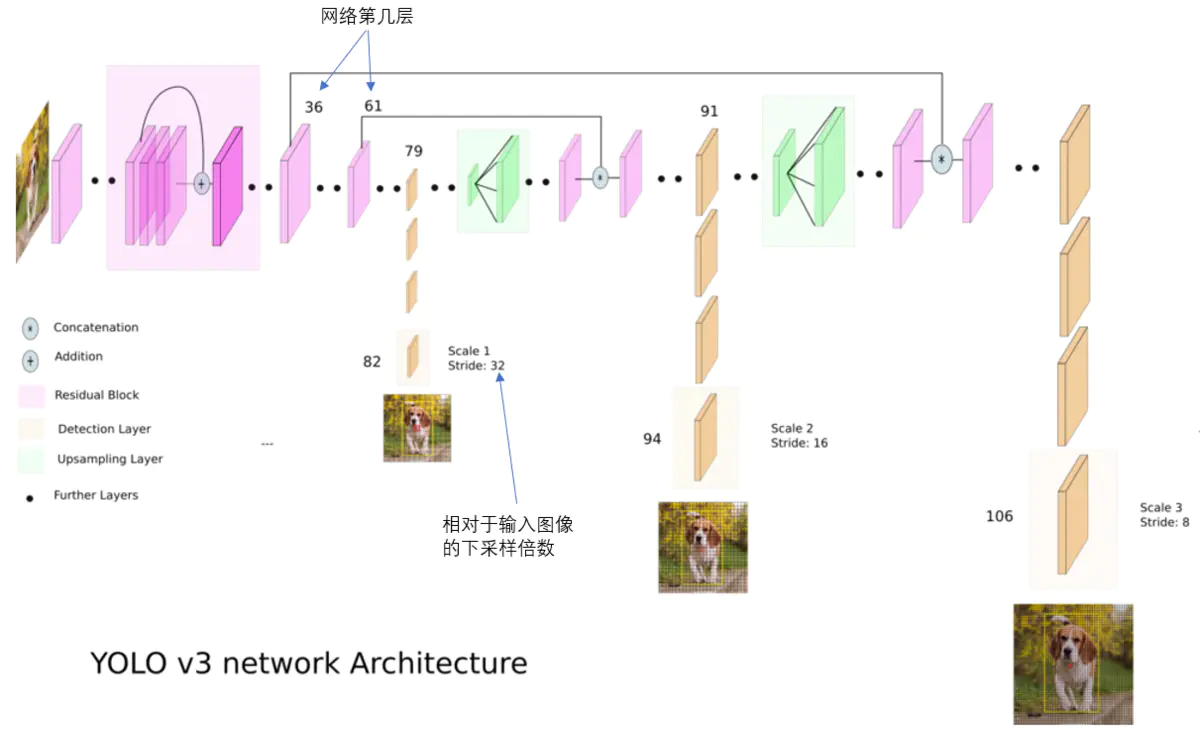
卷积网络在79层后,经过下方几个黄色的卷积层得到一种尺度的检测结果。相比输入图像,这里用于检测的特征图有32倍的下采样。比如输入是416×416的话,这里的特征图就是13×13了。由于下采样倍数高,这里特征图的感受野比较大,因此适合检测图像中尺寸比较大的对象。
为了实现细粒度的检测,第79层的特征图又开始作上采样(从79层往右开始上采样卷积),然后与第61层特征图融合(Concatenation),这样得到第91层较细粒度的特征图,同样经过几个卷积层后得到相对输入图像16倍下采样的特征图。它具有中等尺度的感受野,适合检测中等尺度的对象。
最后,第91层特征图再次上采样,并与第36层特征图融合(Concatenation),最后得到相对输入图像8倍下采样的特征图。它的感受野最小,适合检测小尺寸的对象。
4.9种尺度的先验框
随着输出的特征图的数量和尺度的变化,先验框的尺寸也需要相应的调整。YOLOv2已经开始采用K-means聚类得到先验框的尺寸,YOLOv3延续了这种方法,为每种下采样尺度设定3种先验框,总共聚类出9种尺寸的先验框。在COCO数据集这9个先验框是:(10×13),(16×30),(33×23),(30×61),(62×45),(59×119),(116×90),(156×198),(373×326)。
分配上,在最小的13×13特征图上(有最大的感受野)应用较大的先验框(116×90),(156×198),(373×326),适合检测较大的对象。中等的26×26特征图上(中等感受野)应用中等的先验框(30×61),(62×45),(59×119),适合检测中等大小的对象。较大的52×52特征图上(较小的感受野)应用较小的先验框(10×13),(16×30),(33×23),适合检测较小的对象。
9个anchor会被三个输出张量平分的。根据大中小三种size各自取自己的anchor。每种尺度预测3个box, anchor的设计方式仍然使用聚类,得到9个聚类中心,将其按照大小均分给3中尺度.
尺度1: 在基础网络之后添加一些卷积层再输出
box信息.尺度2: 从尺度1中的倒数第二层的卷积层上采样(x2)再与最后一个16×16大小的特征图相加,再次通过多个卷积后输出
box信息.相比尺度1变大两倍.尺度3: 与尺度2类似,使用了32×32大小的特征图.
每个输出y在每个自己的网格都会输出3个预测框,这3个框是9除以3得到的,这是作者设置的,我们可以从输出张量的维度来看,13×13×255。255是怎么来的呢,3×(5+80)。80表示80个种类,5表示位置信息和置信度,3表示要输出3个
prediction。
5.输入映射到输出
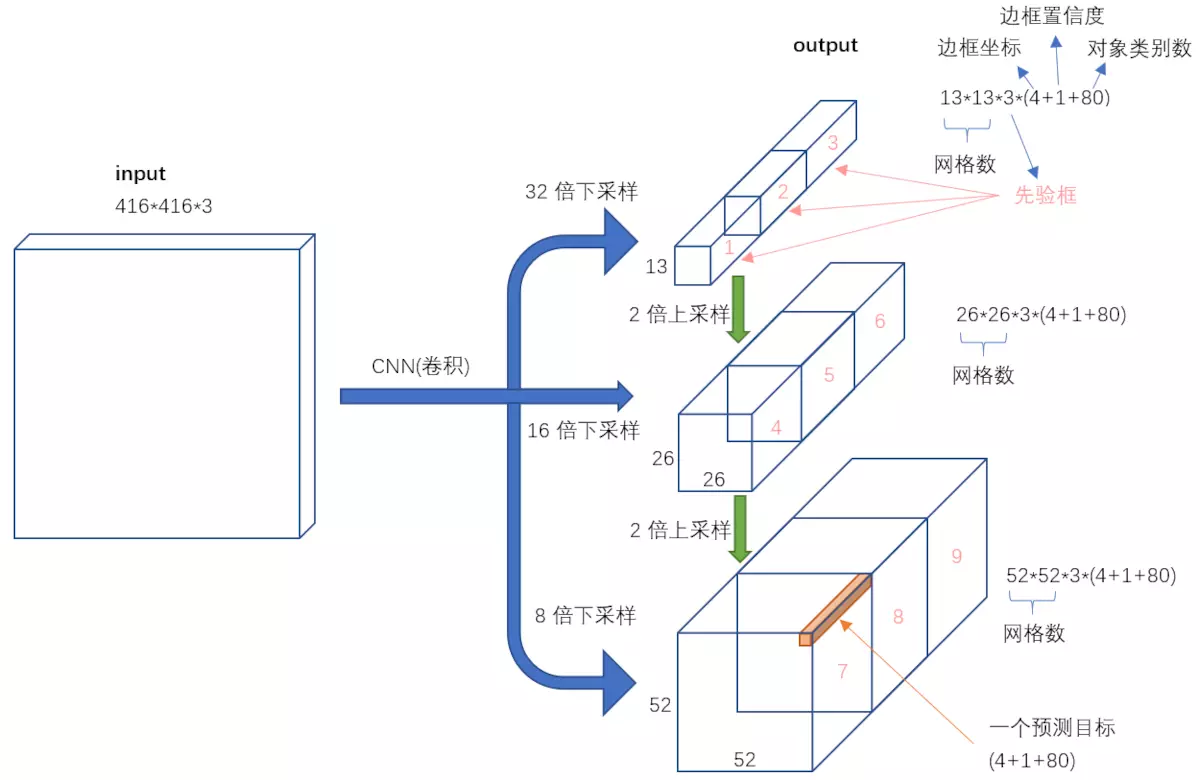
不考虑神经网络结构细节的话,总的来说,对于一个输入图像,YOLOv3将其映射到3个尺度的输出张量,代表图像各个位置存在各种对象的概率。
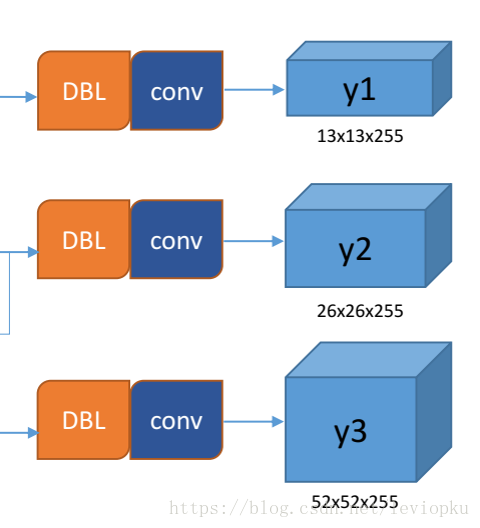
我们看一下YOLOv3共进行了多少个预测。对于一个416×416的输入图像,在每个尺度的特征图的每个网格设置3个先验框,总共有 13×13×3 + 26×26×3 + 52×52×3 = 10647 个预测。每一个预测是一个(4+1+80)=85维向量,这个85维向量包含边框坐标(4个数值),边框置信度(1个数值),对象类别的概率(对于COCO数据集,有80种对象)。
对比一下,YOLOv2采用13×13×5 = 845个预测,YOLOv3的尝试预测边框数量增加了10多倍,而且是在不同分辨率上进行,所以mAP以及对小物体的检测效果有一定的提升。
6.分类器-类别预测:
YOLOv3不使用Softmax对每个框进行分类,主要考虑因素有两个:
Softmax使得每个框分配一个类别(score最大的一个),而对于Open Images这种数据集,目标可能有重叠的类别标签,因此Softmax不适用于多标签分类。Softmax可被独立的多个logistic分类器替代,且准确率不会下降。分类损失采用binary cross-entropy loss。
7.YOLO–>YOLOv2–>YOLOv3总结
YOLOv1会把图像看成一个S×S的栅格,这里的S是等于7,每个栅格预测2个bounding boxes以及栅格含有对象的置信度,同时每个栅格还是预测栅格所属的对象类别;YOLOv1由24层卷积层,4个最大池化层和2个全连接层组成,常规操作,我们关注最后的输出是7×7×30,这里是7×7代表输入图像的7×7栅格,一一对应,30的前十个代表2个bounding boxes的坐标以及对象的置信度,后20个代表VOC数据集的20个类别。YOLOv2:批量归一化,高分辨分类器,锚盒,维度聚类,细粒度特征以及多尺度训练。YOLOv2采用了一个新的基础模型(特征提取器),称为Darknet-19,包括19个卷积层和5个maxpooling层。改进使精度高了,速度方面依然比YOLOv1还要快。
Batch Normalization将数据分布映射到相对紧凑的分布,让网络可以更快以及更好地学习,避免过拟合,使用批归一化这一操作提升了2%mAP。YOLOv1使用224 × 224训练分类器网络,扩大到448用于检测网络。YOLOv2将ImageNet以448×448 的分辨率微调最初的分类网络,迭代10epochs。YOLOv1使用全连接层来生成bounding box的坐标,丢失了特征图的空间信息,造成定位不准,YOLOv2利用锚框直接在卷积特征图滑窗采样,与YOLOv1不同的是,YOLOv2是预测的是坐标相对于栅格左顶点的偏移量,通过变换公式得到最后的预测坐标。YOLOv1只能预测98个边界框,而YOLOv2使用anchor boxes之后可以预测上千个边界框。YOLOv2采用k-means聚类方法对训练集中的边界框做了聚类分析,通过K-means聚类算法将数据集中的ground truth进行了聚类。最后对模型复杂度和召回率的平衡,选择5个聚类中心,挑选了5个最具代表性的bounding box。- 细粒度特征对于检测小物体是有很大的影响,引入了一个
Passthrough Layer,把浅层特征图连接到深层特征图,也就是图中这个26×26×512的特征图通过隔行隔列采样,变换成13×13×2048的特征图,然后和13×13×1024的特征图进行按通道concat。 - 让
YOLOv2对不同尺寸图片的具有鲁棒性,引入了多尺寸的训练,每10batch,选择新的图像尺寸对网络进行训练。
YOLOv3在保持实时性的基础上,对YOLOv2进行了几点改进,主要有三点:
- 使用了残差网络;采用逻辑回归预测置信度和进行分类,从三个尺度上预测
b-box的坐标以及特征提取器发生变化。 - 在分类上,没有使用
softmax多分类,作者也指出softmax最终对性能也没有提升,而且softmax假设是每个box只有一个类,这对迁移到更大有多种类别标签的数据集是没有好处的,对于Open Images这种数据集,目标可能有重叠的类别标签,因此Softmax不适用于多标签分类。所以作者使用多个逻辑回归来预测分类,使用二元交叉熵计算分类损失。 - 借由
FPN的思想,用中间层的输出与后层输出进行融合,进行三个尺度预测,每个尺度的每个cell预测3个坐标,以上面为例,下采样32倍,最后一起的输出是8×8×1024,通过卷积层和逻辑回归得到8×8×255(255=3×(5+80),5是坐标加置信度,80是coco类别),这就是第一个尺度的预测输出,第二个尺度是8×8×1024通过上采样与卷积通过缩放变成16×16×512,然后与上一个stage的16×16×512进行concat,然后通过相似的方式生成16×16×255,类似的操作得到,得到32×32×255。
知识补充(小白扫盲)
1.backbone
Q:深度学习网络中backbone是什么意思?
A1:backbone这个单词原意指的是人的脊梁骨,后来引申为支柱,核心的意思。在神经网络中,尤其是CV领域,一般先对图像进行特征提取(常见的有vggnet,resnet,谷歌的inception),这一部分是整个CV任务的根基,因为后续的下游任务都是基于提取出来的图像特征去做文章(比如分类,生成等等)。
A2:主干网络,用来做特征提取的网络,代表网络的一部分,一般是用于前端提取图片信息,生成特征图feature map,供后面的网络使用。通常用VGGNet还有你说的Resnet,因为这些backbone特征提取能力是很强,并且可以加载官方在大型数据集(Pascal 、Imagenet)上训练好的模型参数,然后接自己的网络,进行微调finetune即可。
2.残差网络
①残差
残差在数理统计中是指实际观察值与估计值(拟合值)之间的差。在集成学习中可以通过基模型拟合残差,使得集成的模型变得更精确;在深度学习中也有人利用layer去拟合残差将深度神经网络的性能提高变强。
②Q:为什么网络深度如此的重要?
A:一般认为神经网络的每一层分别对应于提取不同层次的特征信息,有低层,中层和高层,而网络越深的时候,提取到的不同层次的信息会越多,而不同层次间的层次信息的组合也会越多。
③Q:为什么在残差之前网络的深度最深的也只是GoogleNet 的22 层, 而残差却可以达到152层,甚至1000层?
A:深度学习对于网络深度遇到的主要问题是梯度消失和梯度爆炸,传统对应的解决方案则是数据的初始化(normlized initializatiton)和(batch normlization)正则化,但是这样虽然解决了梯度的问题,深度加深了,却带来了另外的问题,就是网络性能的退化问题,深度加深了,错误率却上升了,而残差用来设计解决退化问题,其同时也解决了梯度问题,更使得网络的性能也提升了。
相关链接
如果对于YOLO和YOLOv2感兴趣可以可以前往参观。
参考
【1】YOLO框架简述
【5】YOLOv3 深入理解

