一、YOLOv2概述
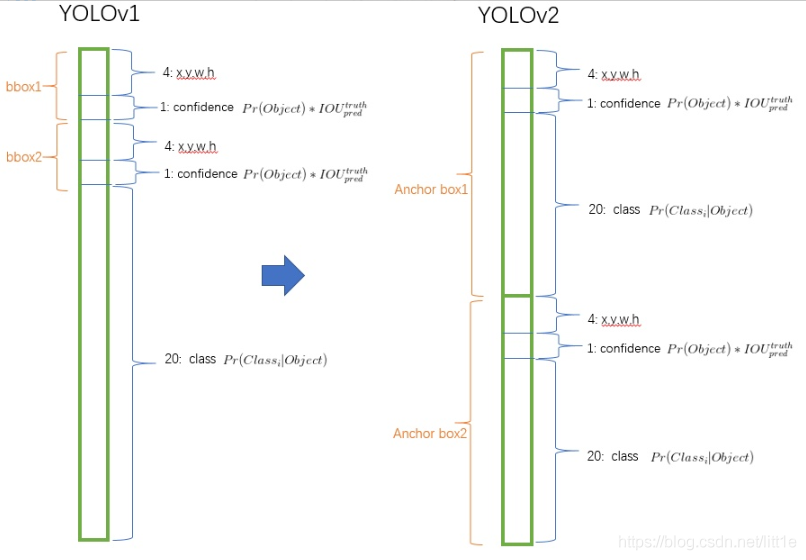
为提高物体定位精准性和召回率,YOLO作者提出了《YOLO9000: Better, Faster, Stronger》(Joseph Redmon, Ali Farhadi, CVPR 2017, Best Paper Honorable Mention),也就是YOLOv2的论文全名,相比YOLO提高了训练图像的分辨率;引入了Faster RCNN中 anchor box的思想,对网络结构的设计进行了改进,使得模型更易学习。YOLOv2的结构示意图如下:

新的YOLO版本论文全名叫“YOLO9000: Better, Faster, Stronger”,相较于YOLO主要有两个大方面的改进:
第一,作者使用了一系列的方法对原来的YOLO多目标检测框架进行了改进,在保持原有速度的优势之下,精度上得以提升。
第二,作者提出了一种目标分类与检测的联合训练方法,通过这种方法,YOLO9000可以同时在COCO和ImageNet数据集中进行训练,训练后的模型可以实现多达9000种物体的实时检测。
二、YOLOv2相较于YOLO的改进
1.Batch Normalization
YOLOv2网络通过在每一个卷积层后添加Batch Normalization,极大的改善了收敛速度同时减少了对其它regularization方法的依赖(舍弃了dropout优化后依然没有过拟合),使得mAP获得了2%的提升。
BN的做法是在卷积池化之后,激活函数之前,对每个数据输出进行规范化(均值为0,方差为1)
2.High Resolution Classifier
YOLOv2增加了在ImageNet数据集上使用448×448的输入来finetune分类网络这一中间过程(10 epochs),这可以使得模型在检测数据集上finetune之前已经适用高分辨率输入。使用高分辨率分类器后,YOLOv2的mAP提升了约4%。
3.Convolutional With Anchor Boxes
YOLOv2则借鉴了Faster R-CNN的思想,移除了YOLOv1中的全连接层而采用了卷积和anchor boxes来预测边界框。
在检测模型中,YOLOv2不是采418×418图片作为输入,而是采用416×416大小。因为YOLOv2模型下采样的总步长为32,对于416×416大小的图片,最终得到的特征图大小为13×13,维度是奇数,这样特征图恰好只有一个中心位置。对于一些大物体,它们中心点往往落入图片中心位置,此时使用特征图的一个中心点去预测这些物体的边界框相对容易些。所以在YOLOv2设计中要保证最终的特征图有奇数个位置。
YOLOv2中引入anchor boxes,输出feature map大小为13×13,每个cell有5个anchor box预测得到5个bounding box,一共有13×13×5=845个box。增加box数量是为了提高目标的定位准确率。
4.Dimension Clusters(维度聚类)
Faster R-CNN中anchor box的大小和比例是按经验设定的,YOLOv2对其做了改进,采用k-means在训练集bbox上进行聚类产生合适的先验框。
由于使用采用标准的k-means欧氏距离会使较大的bbox比小的bbox产生更大的误差,而IOU与bbox尺寸无关,因此使用IOU参与距离计算,使得通过这些anchor boxes获得好的IOU分值。距离公式:
使用聚类进行选择的优势是达到相同的IOU结果时所需的anchor box数量更少,使得模型的表示能力更强,任务更容易学习。算法过程是:将每个bbox的宽和高相对整张图片的比例(wr,hr)进行聚类,得到k个anchor box,将这个比例值乘上卷积层的输出特征的大小.如输入是416×416,那么最后卷积层的特征是13×13.
5.输出层使用卷积层替代 YOLOv1 的全连接层
YOLOv2提出了一种新的分类模型Darknet-19。主要使用3×3卷积并在pooling之后channel数加倍(VGG);global average pooling替代全连接做预测分类,并在3×3卷积之间使用1×1卷积压缩特征表示(Network in Network);使用Batch Normalization来提高稳定性,加速收敛,对模型正则化。Darknet-19的结构如下表:
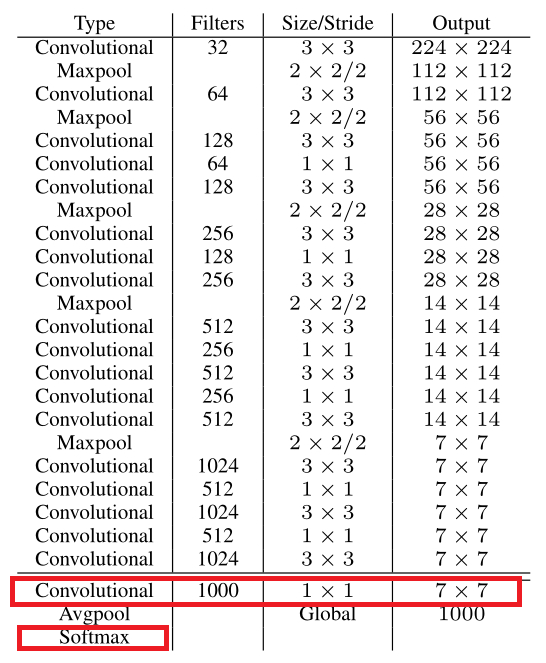
包含19 conv+5 maxpooling。用1×1 卷积层替代YOLOv1的全连接层。1×1 卷积层(为了跨通道信息整合)如上图的红色矩形框部分。
6.Multi-Scale Training
和YOLOv1训练时网络输入的图像尺寸固定不变不同,YOLOv2(在cfg文件中random=1时)每隔几次迭代后就会微调网络的输入尺寸。训练时每迭代10次,就会随机选择新的输入图像尺寸。因为YOLOv2的网络使用的downsamples倍率为32,所以使用32的倍数调整输入图像尺寸{320,352,…,608}。训练使用的最小的图像尺寸为320 ×320,最大的图像尺寸为608 ×608。这使得网络可以适应多种不同尺度的输入。
提示:本文只是总结
知识补充
MAP:
- P——精准率(Precision)
- R——召回率(Recall)
- AP——average precision,一部分理解为PR曲线下的曲线下面积(2010年后),但有部分人理解为相同类别下同一召回率下的的查准率的最大值的平均值(2010年前)
- MAP——mean average precision,多类的检测中,取每个类AP的平均值,即为mAP,现在的图像分类论文基本都是用mAP作为标准。
在MAP的计算过程中,不得不谈的就是p指和R值,准确率或查准率(P值)Accuracy,指分类的准确率,也就是分类准确的样本与样本总数之比。召回率(R值)Recall中文可以翻译为“查全率”或者通常说的“召回率”,也就是返回的结果希望得到的结果占总样本中所有希望的得到的结果的比例。
相关链接
如果对于YOLO和YOLOv3感兴趣可以可以前往参观。
参考
【1】YOLO框架简述
【2】一文看懂YOLOv2

