一、目标检测简单分类
目标检测目前有one-stage和two-stage两种,two-stage指的是检测算法需要分两步完成,首先需要获取候选区域,然后进行分类,比如R-CNN系列;与之相对的是one-stage检测,可以理解为一步到位,不需要单独寻找候选区域,典型的有SSD/YOLO。
二、引言
YOLO(You Only Look Once)是一种基于深度神经网络的对象识别和定位算法,其最大的特点是运行速度很快,可以用于实时系统。YOLO(You Only Look Once)是一种基于深度神经网络的对象识别和定位算法,其最大的特点是运行速度很快,可以用于实时系统。
对象识别和定位,可以看成两个任务:找到图片中某个存在对象的区域,然后识别出该区域中具体是哪个对象。我们想要识别一个目标需要得到两类信息就可以确定一个物体,分别是这个物体的类别和这个物体的位置。
一下面这两张图为例,看到这张图,我们可以看出图中左侧有一只狗,狗的后面有一辆自行车,在图片的右侧有一辆小汽车。那么这一过程放到计算机中应该是怎样的呢?计算机能够识别的也就是下图中右侧的图片。计算机可以识别出这个物体是什么,并且可以用框框标出该物体的位置。

三、YOLO
1.简述YOLO的检测流程
将图片
resize到448×448大小,图片分割得到7×7网格。将图片放到网络里面进行处理:提取特征和预测
卷积部分负责提特征。
全链接部分负责预测:7×7×2=98个
bounding box的坐标和是否有物体的confidence。7×7=49个cell所属20个物体的概率。进行非极大值抑制
(NMS)处理得到结果。
2.结构
YOLO网络结构由24个卷积层与2个全连接层构成,网络入口为448×448(v2为416×416),图片进入网络先经过resize,网络的输出结果为一个张量,维度为
其中,S为划分网格数,B为每个网格负责的边框个数,C为类别个数。每个小格会对应B个边界框,边界框的宽高范围为全图,表示以该小格为中心寻找物体的边界框位置。每个边界框对应一个分值,代表该处是否有物体及定位准确度:t:truth;p:preted),每个小格会对应C个概率值,找出最大概率对应的类别
以本文为例,输出的张量可以写成为:7×7×(2×(4+1)+20)=7×7×30
3.输入和输出的映射关系
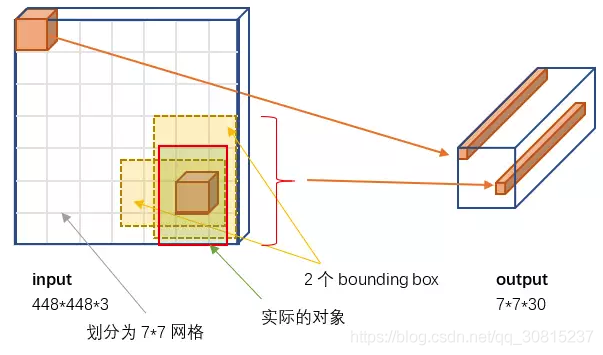
首先我们来解释一下这张图。
(1)输入:原始图像
左侧的input即为输入的部分,唯一的要求是缩放到448×448的大小。这里的3是三通道的意思。主要是因为YOLO的网络中,卷积层最后接了两个全连接层,全连接层是要求固定大小的向量作为输入,所以倒推回去也就要求原始图像有固定的尺寸。那么YOLO设计的尺寸就是448×448。
(2)输出:一个7×7×30的张量(tensor)
右侧的长条即为输出,下面我们将一个小长条放大了看,如下图所示。
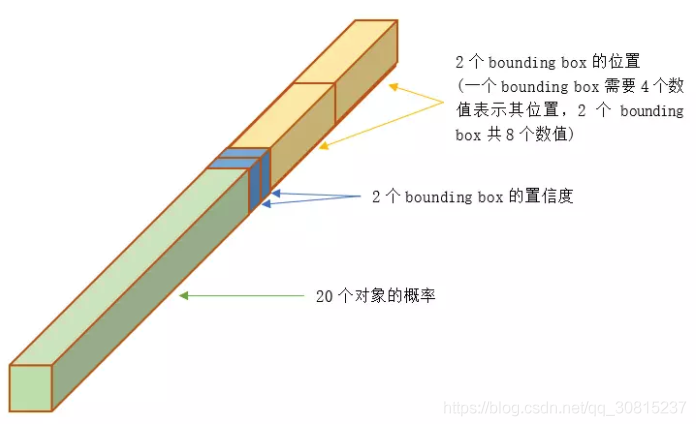
在这张图中,可以分为三个部分,前面的绿色的部分是对象,两个蓝色的部分是bounding box的置信度,后方的两个黄色的部分是两个bounding box的位置信息.
①20个对象分类的概率
YOLO支持识别20种不同的对象(人、鸟、猫、汽车、椅子等),所以这里有20个值表示该网格位置存在任一种对象的概率。
②2个bounding box的位置
每个bounding box需要4个数值来表示其位置,(Center_x,Center_y,width,height),即(bounding box的中心点的x坐标,y坐标,宽度,高度),2个bounding box共需要8个数值来表示其位置。其中坐标的x,y用对应网格的offset归一化到0-1之间,w,h用图像的width和height归一化到0-1之间。
③2个bounding box的置信度
bounding box的置信度 = 该bounding box内存在对象的概率 × 该bounding box与该对象实际bounding box的IOU,公式:
bounding box内存在对象的概率,无论是什么类型的,我们只关注这里是否存在。
bounding box与对象真实bounding box的IOU,体现的是预测的bounding box与真实的bounding box的接近程度。虽然有时说”预测”的bounding box,但这个IOU是在训练阶段计算的。等到了测试阶段(Inference),这时并不知道真实对象在哪里,只能完全依赖于网络的输出,这时已经不需要(也无法)计算IOU了。
综合来说,一个bounding box的置信度Confidence意味着它是否包含对象且位置准确的程度。置信度高表示这里存在一个对象且位置比较准确,置信度低表示可能没有对象或者即便有对象也存在较大的位置偏差。
注意:
class信息是针对每个网格的,confidence信息是针对每个bounding box的。一张图片最多可以检测出49个对象。每个30维向量中只有一组(20个)对象分类的概率,也就只能预测出一个对象。所以输出的 7×7=49个30维向量,最多表示出49个对象。
总共有 49×2=98 个候选区(
bounding box),每个30维向量中有2组bounding box,所以总共是98个候选区。
4.训练
YOLO先使用ImageNet数据集对前20层卷积网络进行预训练,然后使用完整的网络,在PASCAL VOC数据集上进行对象识别和定位的训练和预测。YOLO的网络结构如下图所示:
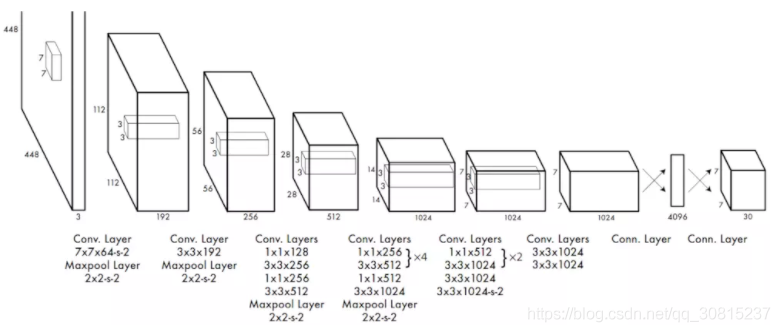
YOLO的最后一层采用线性激活函数,其它层都是Leaky ReLU。训练中采用了drop out和数据增强(data augmentation)来防止过拟合。
5.预测(inference)
训练好的YOLO网络,输入一张图片,将输出一个 7×7×30 的张量(tensor)来表示图片中所有网格包含的对象(概率)以及该对象可能的2个位置(bounding box)和置信度。YOLO采用NMS(Non-maximal suppression,非极大值抑制)算法,从中提取出最有可能的那些对象和位置。
6.NMS(非极大值抑制)
NMS其核心思想是:选择得分最高的作为输出,与该输出重叠的去掉,不断重复这一过程直到所有备选处理完。YOLO的NMS计算方法如下。
网络输出的7×7×30的张量,在每一个网格中,对象Ci第j个bounding box的得分:
它代表着某个对象Ci存在于第j个bounding box的可能性。每个网格有:20个对象的概率×2个bounding box的置信度,共40个得分(候选对象)。49个网格共1960个得分。对每种对象分别进行NMS,那么每种对象有1960/20=98个得分。
NMS步骤如下:
设置一个
Score的阈值,低于该阈值的候选对象排除掉(将该Score设为0)遍历每一个对象类别
遍历该对象的98个得分
①找到Score最大的那个对象及其bounding box,添加到输出列表
②对每个Score不为0的候选对象,计算其与上面①输出对象的bounding box的IOU
③根据预先设置的IOU阈值,所有高于该阈值(重叠度较高)的候选对象排除掉(将Score设为0)
④如果所有bounding box要么在输出列表中,要么Score=0,则该对象类别的NMS完成,返回步骤2处理下一种对象输出列表即为预测的对象
四、YOLO的优点
速度快,处理速度可以达到
45fps,其快速版本(网络较小)甚至可以达到155fps。这得益于其识别和定位合二为一的网络设计,而且这种统一的设计也使得训练和预测可以端到端的进行,非常简便。泛化能力强 ,可以广泛适用于其他测试集。
背景预测错误率低,因为是整张图片放到网络里面进行预测。
五、YOLO的缺点
精度低,小目标和邻近目标检测效果差,小对象检测效果不太好(尤其是一些聚集在一起的小对象),对边框的预测准确度不是很高,总体预测精度略低于Fast RCNN。主要是因为网格设置比较稀疏,而且每个网格只预测两个边框,另外Pooling层会丢失一些细节信息,对定位存在影响。
YOLO与Fast R-CNN相比有较大的定位误差,与基于region proposal的方法相比具有较低的召回率。但是,YOLO在定位识别背景时准确率更高,而 Fast-R-CNN 的假阳性很高。
相关链接
如果对于YOLOv2和YOLOv3感兴趣可以可以前往参观。
参考
【1】超全面目标检测算法综述
【2】YOLO框架简述

